Modern Data Pipeline
A scalable ETL pipeline built with Apache Airflow, Spark, and dbt for processing large-scale datasets from Hugging Face.
🚧 WIP
This project is under active development. Architecture Image
Overview
This pipeline processes Japanese text data from HuggingFace datasets, demonstrating modern data engineering practices with:
- Streaming data ingestion
- Distributed processing
- Data quality validation
- Analytics transformations
Architecture
Architecture Image
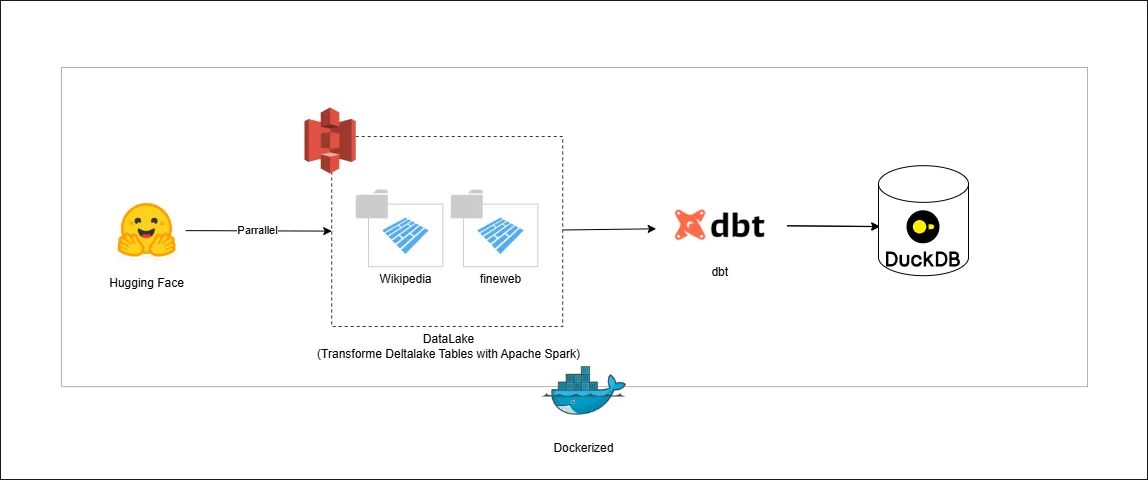
Core Components
- Apache Airflow - Workflow orchestration and scheduling
- MinIO - S3-compatible object storage for data lake
- DuckDB - In-process analytics database
- dbt - Data transformation and modeling
- Docker - Containerized deployment
- Spark - Distributed processing (container ready for FastAPI service)
Data Flow
- Extract: Stream data from HuggingFace datasets
- Transform: Process data in configurable chunks
- Store: Save as Parquet files in MinIO
- Load: Import into DuckDB for analytics
- Model: Run dbt transformations for data quality and insights
Current Implementation
Data Sources
- HuggingFace FineWeb - Japanese web text corpus (380M+ rows)
- Wikipedia Japanese - Japanese Wikipedia articles (10M+ rows)
Processing Strategies
The pipeline supports multiple execution strategies:
test- Small sample for testing (1,000 rows)memory_optimized- Conservative memory usageconservative- Balanced approachbalanced- Standard processingaggressive- Maximum throughput
Features
- ✅ Streaming data ingestion with memory management
- ✅ Chunked processing with configurable batch sizes
- ✅ Data quality validation and reporting
- ✅ dbt models for analytics (content analysis, quality metrics)
- ✅ Comprehensive error handling and fallback mechanisms
- ⚠️ FastAPI service integration (client implemented, service pending)
- ⚠️ Delta Lake support (planned)
Quick Start
Prerequisites
- Docker and Docker Compose
- 8GB+ RAM recommended
- 50GB+ disk space for data storage
Setup
-
Clone the repository and navigate to the project directory
-
Create
.envfile from sample:
cp .env.sample .env- Start the services:
docker-compose up -d-
Wait for services to initialize (2-3 minutes)
-
Access the services:
- Airflow UI: http://localhost:8080 (admin/admin)
- MinIO Console: http://localhost:9001 (minioadmin/minioadmin123)
Detailed Startup Instructions
Apache Airflow Setup
- Initialize Apache Airflow:
docker compose up airflow-init- Start Apache Airflow services:
docker compose up-
Access Airflow Web UI:
- Navigate to
localhost:8080 - Login credentials:
username: admin password: admin
- Navigate to
-
Start the pipeline:
- Click on
local_data_processing_fastapiDAG - Click the play/start button to trigger execution
- Click on
Memory-Optimized Setup
For systems with limited memory:
# Install dependencies
uv sync
# Apply memory-optimized Docker configuration
docker compose -f docker-compose.yml -f docker-compose.override.yml up airflow-init
# Start services with memory limits
docker compose -f docker-compose.yml -f docker-compose.override.yml upPipeline Execution Modes
Configure execution patterns by setting the EXECUTION_MODE environment variable:
# 1. Sample mode (test, 5-10 minutes)
export EXECUTION_MODE=memory_optimized
# Run local_data_processing DAG in Airflow UI
# 2. Full processing (Conservative, ~12 hours)
export EXECUTION_MODE=conservative
# Run local_data_processing DAG in Airflow UI
# 3. dbt standalone execution
cd duckdb_pipeline
dbt run --vars '{"batch_id": "20250623"}'
dbt test # Run comprehensive test suite
dbt docs generateAccessing DuckDB
Multiple methods to access the DuckDB database:
# 1. Via Airflow container using DuckDB CLI
docker compose exec webserver duckdb /opt/airflow/duckdb_pipeline/duckdb/huggingface_pipeline.duckdb
# 2. Via Python in Airflow container
docker compose exec webserver python -c "
import duckdb
conn = duckdb.connect('/opt/airflow/duckdb_pipeline/duckdb/huggingface_pipeline.duckdb')
print('Available tables:', [t[0] for t in conn.execute('SHOW TABLES;').fetchall()])
conn.close()
"
# 3. Using local DuckDB CLI (requires local duckdb installation)
duckdb duckdb_pipeline/duckdb/huggingface_pipeline.duckdb
# Sample queries in DuckDB CLI:
# .tables # List all tables
# SELECT COUNT(*) FROM wikipedia; # Wikipedia record count
# SELECT COUNT(*) FROM fineweb; # FineWeb record count
# SELECT * FROM mart_japanese_content_summary; # Japanese content summary
# .quit # Exit CLIMinIO Access
- Access MinIO Console:
- Navigate to
localhost:9001 - Login credentials:
username: minioadmin password: minioadmin
- Navigate to
Data Quality and Anomaly Detection
The pipeline includes built-in data quality checks and anomaly detection through dbt models and Python scripts integrated into the DAG. Currently, Japanese language quality checks are implemented within the dbt transformation process.
Running the Pipeline
- Open Airflow UI at http://localhost:8080
- Enable the
local_data_processing_fastapiDAG - Trigger a manual run with config:
{
"execution_strategy": "test",
"max_rows": 1000
}Project Structure
.
├── dags/
│ ├── dags.py # Main DAG definition
│ ├── huggingface_utils.py # HuggingFace data utilities
│ └── fastapi_delta_tasks.py # FastAPI client (for future service)
├── duckdb_pipeline/ # dbt project
│ ├── models/
│ │ ├── staging/ # Raw data staging
│ │ └── marts/ # Business logic models
│ └── dbt_project.yml
├── scripts/
│ └── minio_setup.py # Storage initialization
├── spark/ # Spark container config
├── docker-compose.yml # Service orchestration
└── requirements.txt # Python dependenciesMonitoring
Pipeline Status
- Check DAG runs in Airflow UI
- View task logs for detailed execution info
- Monitor data quality reports in task outputs
Storage
- MinIO dashboard shows bucket usage and object counts
- Parquet files organized by dataset and date
Development
Adding New Data Sources
- Create a new extraction function in
huggingface_utils.py - Add corresponding task in the DAG
- Create staging and mart models in dbt
Modifying Processing Logic
- Adjust chunk sizes and strategies in DAG configuration
- Update memory limits in
huggingface_utils.py - Modify dbt models for new analytics requirements
Roadmap
- Implement FastAPI service for real-time processing
- Add Delta Lake for ACID transactions
- Integrate Snowflake for cloud analytics
- Add more data sources and transformations
- Implement data lineage tracking
- Add comprehensive monitoring and alerting
Troubleshooting
Common Issues
-
Out of Memory Errors
- Use a more conservative execution strategy
- Reduce chunk sizes in configuration
-
MinIO Connection Errors
- Ensure MinIO is running:
docker-compose ps - Check MinIO logs:
docker-compose logs minio
- Ensure MinIO is running:
-
DAG Import Errors
- Check Airflow scheduler logs
- Verify Python dependencies are installed
Cloud Implementation
This section outlines the managed services available for building data pipelines on AWS, Azure, and GCP. Snowflake is included as a multi-cloud, fully-managed data warehouse solution with high-performance query capabilities.
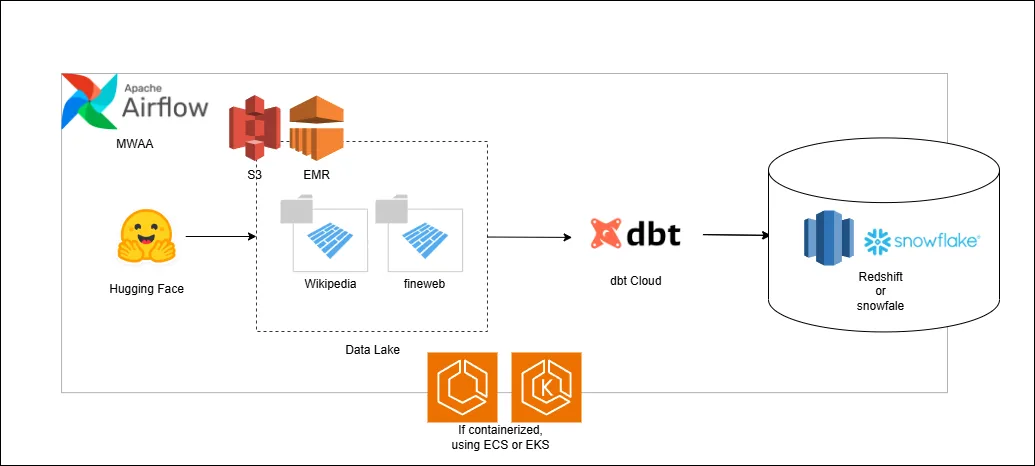
AWS Services
- Data Warehouse
- Amazon Redshift or Snowflake
- Data Lake
- S3
- Delta Lake
- Pipeline Orchestrator
- MWAA (Managed Workflows for Apache Airflow) or Apache Airflow on ECS
- Big Data Processing
- EMR (Elastic MapReduce) or AWS Glue
- ETL Tool
- dbt Cloud
- Containerization
- ECS / EKS
License
This project is licensed under the MIT License.